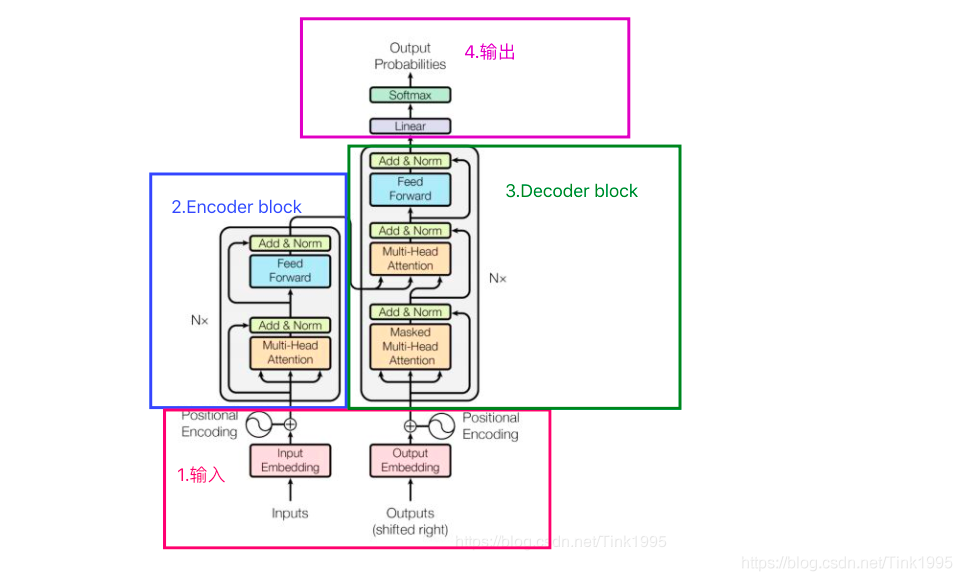
图中所示是chatgpt的结构,为
transformer模型,由
谷歌首次提出。
ChatGPT的大模型整体原理是:根据上文生成下文
ChatGPT的一句话并不是直接生成的,而是一个词一个词"蹦"出来的
词向量是一种把词汇映射到高维向量(或称为点)的方法,通过不断的迭代演化,我们可以得到词汇间的关系,相似或通常在一起的词汇在高维空间中会更接近
通过词向量技术,我们可以让AI理解
人话,并把
AI话转成
人话,是transformer模型中输入和输出的重要部分
输入即将上文(ChatGPT说过的词和用户问的话)输入进模型
什么是
positional encoding?这是位置标记,这样AI便不会把'Tom chase Jerry'理解成'Jerry chase Tom'
这是两个神经网络,OpenAI团队运用了一种特殊的小模型转大模型方法
OpenAI团队首先训练出小模型,接下来运用了一个技巧把小模型参数转为大模型参数,减少了训练成本(大家可以上Arxiv搜索Greg Yang的论文详细了解)
根据Decoder的输出,'输出'部分可以将数据转为词汇
(引用自某篇CSDN文章)
Transformer虽然好,但它也不是万能的,还是存在这一些不足:
优点:
1.效果好
2.可以并行训练,速度快
3.很好地解决了长距离依赖的问题
缺点:
1.完全基于self-attention,对于词语位置之间的信息有一定的丢失,虽然加入了positional encodeing来解决,但仍可以优化